Simulation staff need to understand research theory either to fully participate in their own department’s research or to review the current literature with a view to improving their simulation program. In either case, all research should clearly identify how data was collected and what potential sources of error exist. In this article, we learn that in order for research data to be of use, any assessment (aka questionnaire/instrument) must be both reliable and valid.
This is the second article devoted to research discusses the validity and reliability of data collection for simulation champions. For the first article, please see Understanding Research for Clinical Simulation – The Scientific Process. Let’s quickly recap from that article why all simulation staff should appreciate the research process:
Understanding research and its use in guiding EBP is not only important for ensuring that patients receive the best possible care, but also for finding and implementing the best simulation methodologies. In the early part of this century there was little research to support the use of medical simulation as an effective educational tool, however in the past fifteen years or so, extensive research has clearly revealed the benefits of simulation. In addition, medical simulation is being used to research new procedures, protocols and equipment before patients are exposed to potentially harmful interventions. Simulation team members need to understand research principals so that they can evaluate current research data and thus make informed decisions about the use of new clinical simulation methodologies.
Reliability of Research Data
Reliability refers to the repeatability of findings. If the study were repeated, would it give the same results? If the answer is yes, the data are reliable. If more than one person is observing behavior or some event, all observers should agree on what is being recorded in order to claim that the data are reliable.
- Reliability is the degree of consistency of an assessment tool when it is used more than once.
- In other words, the results are stable and consistent and the test is repeatable.
- There are different types of reliability each with several techniques for measuring the reliability. A numerical value known as the reliability coefficient is applied to each technique.
- Internal Stability aka test-retest reliability
- The same people get the same test on separate occasions and get the same results.
- Results are compared and correlated with the first test to give a measure of stability
- E.g. Spearman-Brown coefficient.
- Scores equal or greater than 0.7 may be considered sufficient by some researchers although other researchers prefer a higher coefficient.
- The same people get the same test on separate occasions and get the same results.
- Internal Consistency
- A measure used to evaluate the degree to which different test items that measure the same construct produce similar results.
- E.g. Split-Half
- This process starts by splitting in half all items of a test that are intended to probe the same area of knowledge
- A correlation between the two groups is calculated.
- This process starts by splitting in half all items of a test that are intended to probe the same area of knowledge
- Cronbach’s Alpha
- This method involves correlating pairs of items that measure the same construct and then averaging the results from the individual pairs.
- Equivalence – Inter-rater reliability aka interobserver agreement
- This determines if the judges (observers or raters), using the same instrument, are measuring the same assessment equivalent
- This is important because observers may be subjective and their assessments may not be the same.
- When different observers assign grades to simulation activities, the observers may score the same skills or behaviors differently.
- E.g.Cohen’s Kappa
- Historically, percent agreement (number of agreement scores / total scores) was used to determine interrater reliability.
- However, the raters could be guessing. Cohen’s kappa takes this into the consideration. The Kappa statistic varies from 0 to 1, where.
- Internal Stability aka test-retest reliability
- 0 = agreement equivalent to chance.
- 0.1 – 0.20 = slight agreement.
- 0.21 – 0.40 = fair agreement.
- 0.41 – 0.60 = moderate agreement.
- 0.61 – 0.80 = substantial agreement.
- 0.81 – 0.99 = near perfect agreement
- 1 = perfect agreement.
Validity of Research Data
Validity simply means that a test or instrument is accurately measuring what it is supposed to measure. There are a number of different types of validity, some of which are listed below:
- Face Validity – the weakest form of validity but can be used to eliminate weak or poorly designed studies.
- Maybe used by experts in the field of research being studied.
- Sometimes used by stakeholders to determine worthiness of research for funding. If stakeholders can not see an obvious connection, they may withhold funding.
- E.g. People who are less than 5 feet tall sing better than taller people!! On face value this is ridiculous.
- E.g. An instrument designed to measure stress experienced by novice simulation students has few questions related to anxiety, then on face value, this would not appear to be a useful instrument.
- Construct (Content) Validity
- A construct is the “something” you are actually trying to measure.
- Valid construct e.g. height, weight, knowledge of a particular subject, lab results.
- Measurements that may have debatable content validity e.g. multiple choice nursing exams used as a estimate of bedside communication ability or questions that use such complicated language that the test takers have to focus on understanding the question rather than answering a question about the construct.
- A construct is the “something” you are actually trying to measure.
- Criterion Related Validity – the extent to which people’s scores on one measure (construct) might correlated with people’s scores on another measure. These tests are used to predict present or future performance.
- E.g. Competency in new grad program simulation scenarios and future performance as an RN.
- E.g. GRE performance and success in graduate programs.
- Formative Validity – when applied to outcomes assessment it is used to assess how well a measure is able to provide information to help improve the program under study.
- When designing a rubric for a simulation scenario, one could assess a student’s knowledge about management of diabetes. If the students do well in all areas except for management of hypoglycemia, this is useful information since changes can be made to the program to improve student’s knowledge about this topic.
- Other types of validity include:
- Sampling Validity
- Concurrent Validity
- External Validity
- Statistical Conclusion Validity
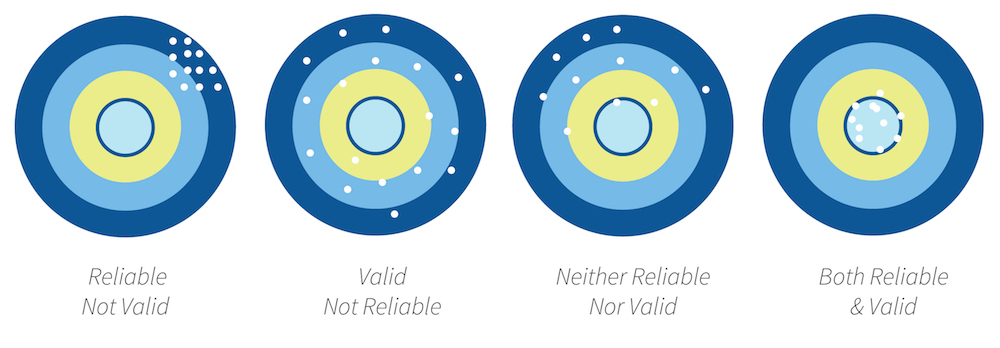
If data are valid, it must be reliable. If people receive very different scores on a test every time they take it, the test is not likely to predict anything however, if the same or similar scores are obtained the test is reliable. The opposite may not always be true in that a test may not be valid even if it is reliable. For example, a student may repeatedly measure blood pressure accurately, but this does not mean that the student will select the right intervention for an abnormal blood pressure.
Simply put, think of a bullseye. Only arrows that consistently hit the bullseye are both reliable, and valid!
In summary, healthcare interventions and educational strategies including simulation are tested to ensure that they work. Researches evaluate their measures by identifying the reliability and validity of their studies. Reliability is consistency across time (test-retest reliability), across items (internal consistency), and across researchers (interrater reliability). Validity is the extent to which the scores actually represent the variable they are intended to.
Understanding Research for Clinical Simulation Series:
-
- Part 1: The Scientific Process
- Part 2: Validity and Reliability
- Part 3: Statistics
- Part 4: P Values
Learn more about Understanding Research Data Through Validity and Reliability!
Today’s article was guest authored by Kim Baily PhD, MSN, RN, CNE, previous Simulation Coordinator for Los Angeles Harbor College and Director of Nursing for El Camino College. Over the past 16 years Kim has developed and implemented several college simulation programs and previously chaired the Southern California Simulation Collaborative.
Have a story to share with the global healthcare simulation community? Submit your simulation news and resources here!